The running science “nerd alert”
from Thomas Solomon PhD
 and Matt Laye PhD
and Matt Laye PhD 
August 2022
Usually, we compile a short list of recently-published papers in the world of running science and break them into bite-sized chunks so you can digest them as food for thought to help optimise your training. But, things changed in 2022 and we focused on an ambitious project that is consuming all our spare time — a systematic review and meta-analysis. So, this month's instalment of our “Nerd Alert” will explain what a systematic review is and what topic we are systematically reviewing. As usual, to help wash it all down, we’ve also reviewed our favourite beer of the month. Enjoy...
Click the title of each section to read more.
 What is the difference between a narrative review and a systematic review?
What is the difference between a narrative review and a systematic review? A narrative review typically tells a story, based on available evidence, to review a topic and/or answer a question and/or propose a new idea. A narrative review has no standard format and no clearly specified method of identifying, selecting, and validating the inclusion of information. Therefore, it is easy to highlight and cherry-pick whatever evidence you like to fit your hypotheses (beliefs) about a topic. This creates bias. Furthermore, no data is analysed to quantitatively summarise info from multiple studies. We’ve written several narrative reviews over the years but, until now, we’ve never written a systematic review.
A systematic review focuses on a specific question — what is the effect of a specific treatment on a specific variable of interest (aka the primary outcome)? It uses a clear, pre-planned scientific method to identify all known scientific evidence from separate research studies examining the same topic, appraise the quality of the evidence, and generate an objective summary of the knowledge of a specific intervention (e.g. a drug, supplement, or exercise). Some systematic reviews also include a quantified analysis of all the compiled data — a meta-analysis — to objectively determine the overall effect size of the treatment.
In a meta-analysis, the most common approach is to do a “summary statistic meta-analysis”, where the mean (average) and standard deviation (spread) of the variable of interest from each study are used to calculate an overall effect size estimate. Another type of meta-analysis is an “individual participant data meta-analysis” where all raw study data is compiled into a new database — this is the best type of meta-analysis but it is not always possible to obtain individual subject raw from authors’ studies (due to authors being unable to share data due to ethical approval restrictions that restrict patient data sharing but also because authors do not want to share their data — yes that is a thing).
What is the point of a systematic review? — Evidence-based practice is the process of integrating of the best available high-quality scientific evidence with clinical (or coach/athlete) expertise and patient (or athlete) values/feedback.
— This process eventually informs public health policy or, in our case, sports practice recommendations.
— A systematic review plays an important role in this process because it identifies and summarises the best available high-quality scientific evidence.
What steps are involved in completing a systematic review?  Gather a research team.
Gather a research team.
 Formulate a question and develop a clear, transparent, and reproducible protocol.
Formulate a question and develop a clear, transparent, and reproducible protocol.
 Search for and identify studies (ideally randomised controlled trials) that address your question.
Search for and identify studies (ideally randomised controlled trials) that address your question.
 Evaluate the quality and “risk of bias” of the studies.
Evaluate the quality and “risk of bias” of the studies.
 Extract and meta-analyse the data, interpret and discuss the findings, and make an overall conclusion about the body of evidence.
Extract and meta-analyse the data, interpret and discuss the findings, and make an overall conclusion about the body of evidence.
 Write a report and publish it.
Write a report and publish it.
 When new evidence becomes available, use the same protocol to update the review.
Why is a systematic review of randomised controlled trials preferable?
When new evidence becomes available, use the same protocol to update the review.
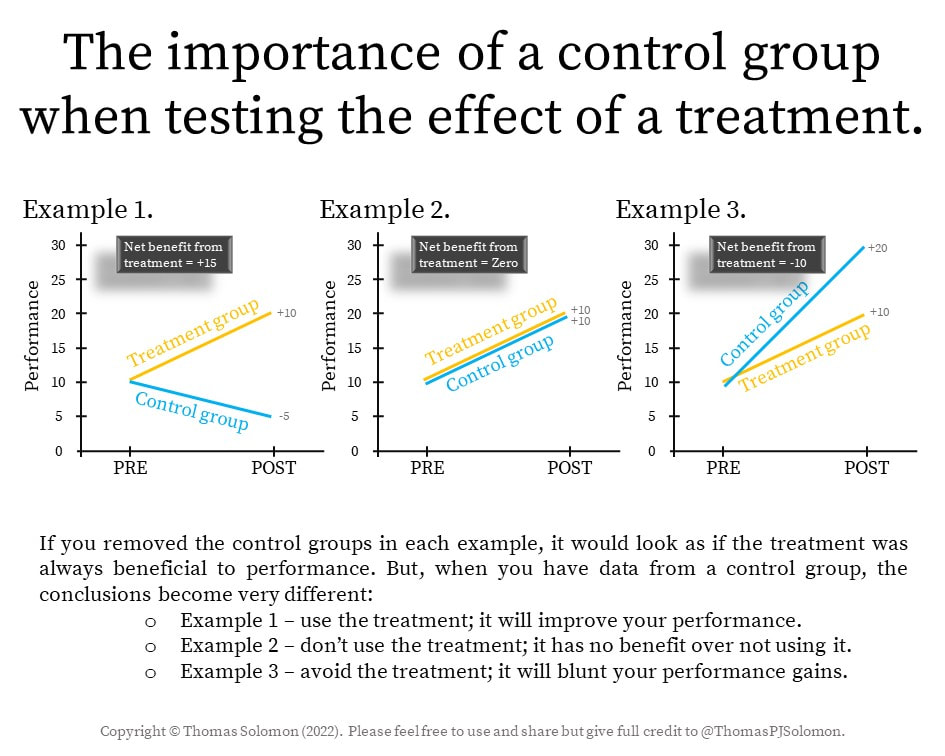
Why is a systematic review of randomised controlled trials preferable? — Randomised controlled trials (RCTs) contain a treatment group AND a control group.
— This means that a group of folks is randomly assigned to one of two groups. In one group they receive the treatment intervention (e.g. a drug, supplement, exercise, etc); in the other group, they do not. Before and after the intervention — which can be minutes, hours, days, weeks, months, or even years — the variable of interest (aka the primary outcome) is measured (e.g. endurance performance) and the change in this variable is compared between the treatment (e.g. heat acclimation + training) and control (e.g. training only) groups.
— The control group is golden — without a control group you have no way of knowing whether an increase in performance is due to the treatment (heat acclimation) or due to the natural time course of change (during training).
— To conceptualise this, a 10-unit increase in performance in the treatment group (heat acclimation + training) might sound OK. But, if performance gets worse by 5 units in the control (training only) group then the 10-unit increase in performance in the treatment group is actually underestimating the real effect: compared to control, the treatment improves things by 15 units (10 minus -5 = 15). Without a control group, you would not know this. Now imagine that there is also a 10-unit increase in performance in the control group. In that case, there is no effect of treatment at all (10 minus 10 = zero). Now imagine that there is a 20-unit increase in performance in the control group — in that case, the treatment is actually blunting the training-induced improvement in performance.
 What are the strengths of a systematic review?
What are the strengths of a systematic review? — A systematic review summarises the current scientific evidence on a specific topic using a clear, pre-planned scientific method to identify all known scientific evidence on the topic. By utilizing all of the known data a systematic review doesn't just rely on your favorite study that showed what you want it to but rather takes the totality of evidence — positive, neutral, and bad — looking for the big picture.
— Since the protocol is registered and open-access, a systematic review protocol is reproducible so its findings can be updated when new evidence emerges.
— A systematic review prevents the “cherry-picking” that can occur in narrative reviews.
— A systematic review with a meta-analysis generates an effect size estimate — this is useful because an effect size is a standardised measure of the effect of a treatment and they can be used to infer the magnitude of an effect. For example, an effect size of less than 0.2 is considered a trivial effect, 0.2 to 0.5 is small, 0.5 to 0.8 is moderate, 0.8 to 1.2 is large, 1.2 to 2 is very large and greater than 2 is a huge effect.
— The meta-analysis also generates a 95% confidence interval around the effect size. This is useful because we’d like to know how certain the effect size estimate is. The 95% CI is a margin of uncertainty — i.e. a range of values within which the true effect size would be found 95% of the time if the data was repeatedly collected in different samples of people. Remember that studies contain small samples of people from which we are trying to estimate the effect on the entire target population. E.g. if an effect size of 0.2 is found in 20 endurance athletes; how confident are we that this effect size is a good estimate for all endurance athletes? If the 95% confidence interval is 0.15 to 0.25, we can be confident that 0.2 is a good estimate and say that there is a small effect size but if the 95% confidence interval is -0.3 to 0.7, we would have little confidence in the estimate and conclude that there is not likely an effect of the treatment. Basically, the 95% confidence interval of the effect size is a range of plausible values for the population estimate — if the range is small we can be more confident in the estimate but if the range of values crosses zero, there is no effect.
What are the weaknesses and/or limitations of a systematic review? — “Garbage in, garbage out”... This expression refers to a systematic review of terrible studies that are full of bias (garbage in) being compiled in a terribly-constructed systematic review producing an overall effect size estimate that is unreliable and, therefore, misleading (garbage out).
— While the individual studies included in a systematic review contain bias, so too does the systematic review itself — bias can and is introduced at any stage of the process during which evidence is collected and summarised. For this reason, a systematic review includes an assessment of bias to help bolster the reliability of the findings.
— One aspect of bias is publication bias, which is the publication of only positive findings. Many studies with negative findings never get published. Although statistical tests are used to help detect publication bias, they have limited sensitivity to detect it. Therefore, publication bias can hurt the validity of a systematic reviews. It’s like the athlete that only shares their best results or only the training leading up to their best day — useful yes; but for the whole picture, definitely not.
Are the findings from a systematic review useful in practice? Yes.
The entire point of a systematic review is to evaluate the entirety of the scientific evidence and perform a meta-analysis to derive an overall effect size estimate that can be used to inform whether or not the intervention is likely to be of use in practice.
Link to our registered protocol: click here
What is the research question?
The purpose of our systematic review is to answer the question:
Why are we asking this research question?
— Heat acclimation is a popular training modality for athletes preparing for races in hot conditions.
— Traditionally, heat acclimation involves a purposeful series of training sessions in the heat (e.g. treadmill running in a sauna or heat chamber) during the month prior to the race — this is called “active” heat acclimation.
— Although this approach can induce adaptations associated with heat acclimation (increased sweat rate, shorter time to sweat onset, lower heart rate, and RPE during exercise), it has limitations because not everyone has access to a treadmill/bicycle in a sauna and not all of your sessions (e.g. technical mountain sessions) can be done in a sauna. Furthermore, because the heat forces you to train at a lower absolute intensity, “active” heat acclimation interferes with your normal training.
— Another common approach is “passive” heat acclimation in which one just sits in a sauna or hot tub daily without exercise. While some evidence shows this can effectively induce some aspects of heat acclimation such as lower heart rate, increased sweating, and lower core temperature (see here & here), this sometimes requires at least 1-hour of heat exposure per day.
— A contemporary approach to heat acclimation is adding “passive” heat exposure after exercise in normal temperatures. This can be achieved using a sauna or hot water immersion (having a bath) or by wearing a hot-water perfused body suit to maintain an elevated core body temperature after your exercise sessions. This might be more efficient than passive-only approaches.
— We recently noticed an increase in the number of studies examining the effects of post-exercise “passive” heat acclimation on exercise performance but no systematic review of the evidence exists. We will fill that gap with our review.
How are we going to answer the research question?
— We will complete a systematic review of all known randomised controlled trials (RCTs) published in peer-reviewed journals examining the effect of post-exercise heat exposure on exercise performance. Note: RCTs are studies where participants are randomised to receive a treatment intervention or a control intervention and the variables of interest are measured before and after the interventions in both groups.

The text beyond this point goes pretty deep into our actual systematic review process. If you’re feeling nerdy and wanna learn more, keep reading. But, if you’re bored and have read enough, click here to skip ahead to our beer.
How did we search for published randomised controlled trials (RCTs)?
— To ensure consistency in our search for papers, we dissected our question into Population, Interventions, Comparison group, & Outcomes. This helped us include only papers including the following:
— We planned our search strategy in January 2022 and, to maximise quality, we recruited Professor Janice Thompson (University of Birmingham, UK) to independently peer-review our strategy using standard guidelines (the 2015 Peer Review of Electronic Search StrategiesGuideline Statement).
— This process resulted in a specific search phrase that we could use when searching for papers.
— Our initial search was conducted in April 2022 and we searched several databases including MEDLINE, EMBASE, CENTRAL, and clinical trials databases for unpublished data (ClinicalTrials.gov, WHO International Clinical Trials Registry Platform, and EU Clinical Trials Register).
— Since many months will pass between the planning stage and the final data analysis, we will run the search again shortly before the final report is written to capture any new papers that have recently been published.
What did we do with all the studies after our search?
— The search hits were downloaded into a reference manager software (Endnote) and we independently screened the studies, coding each study as “include” or “exclude” in line with our inclusion and exclusion criteria. Our initial search identified about 2000 studies, so this process took many hours.
— After our independent search and screening, we met to cross-check our findings and to agree on a final list of included studies. Any unresolved disagreements were resolved by our independent strategy peer-reviewer, Janice Thompson.
— Full-text versions of the included papers were downloaded and we independently assessed the quality of the individual studies using a standardised method (the Cochrane Risk of Bias tool), coding papers as either “low” or “high” risk of bias or “some concerns”. Once again, we met to cross-check our findings and agree on a final assessment of bias. This process will help us with the meta-analysis (more on that later).
— Next, we independently extracted data from the included papers. This included:
— Some of the data was not available in the papers so have requested it from the study authors. (This is the stage we are currently at and we are awaiting responses from study authors.) If authors don’t reply or do not share their data, we will use Web Plot Digitizer software to scan and extract data from the figures in the papers.
What will we do with the data?
— Before any statistical analysis, we will first write a narrative of the included studies, in which we will “Describe, Interpret, Evaluate, and Conclude”. This will include a narrative of between-study heterogeneity (e.g. variation in sample sizes, study designs, interventions, subject types, etc, among the included studies). This is called a “qualitative” synthesis. After that, the “quantitative” synthesis (the meta-analysis) will begin…
— A meta-analysis determines the overall effect of an intervention. In this case, the overall effect of post-exercise heat exposure on exercise performance. Effect sizes for each study will be calculated as the between-group (treatment vs. control; or, heat vs. no heat) standardised mean difference (SMD) for each outcome in the included studies. Effect sizes are useful because they are a standardised measure of the experimental effect and can be used to infer the magnitude of the effect — an effect size of less than 0.2 is considered a trivial effect, 0.2 to 0.5 is small, 0.5 to 0.8 is moderate, 0.8 to 1.2 is a large, 1.2 to 2 is very large and greater than 2 is a huge effect.
— Effect size estimates will be compiled and meta-analysed using Meta-Essentials software.
— We will build forest plots to summarise the effect size estimates and the corresponding 95% confidence intervals, i.e. a margin of uncertainty — i.e. the range of plausible values within which the true effect size would be found 95% of the time if the data was repeatedly collected in different samples of people — basically, if the 95% confidence interval crosses zero, there is no effect. This will help us calculate the overall effect of post-exercise heat exposure.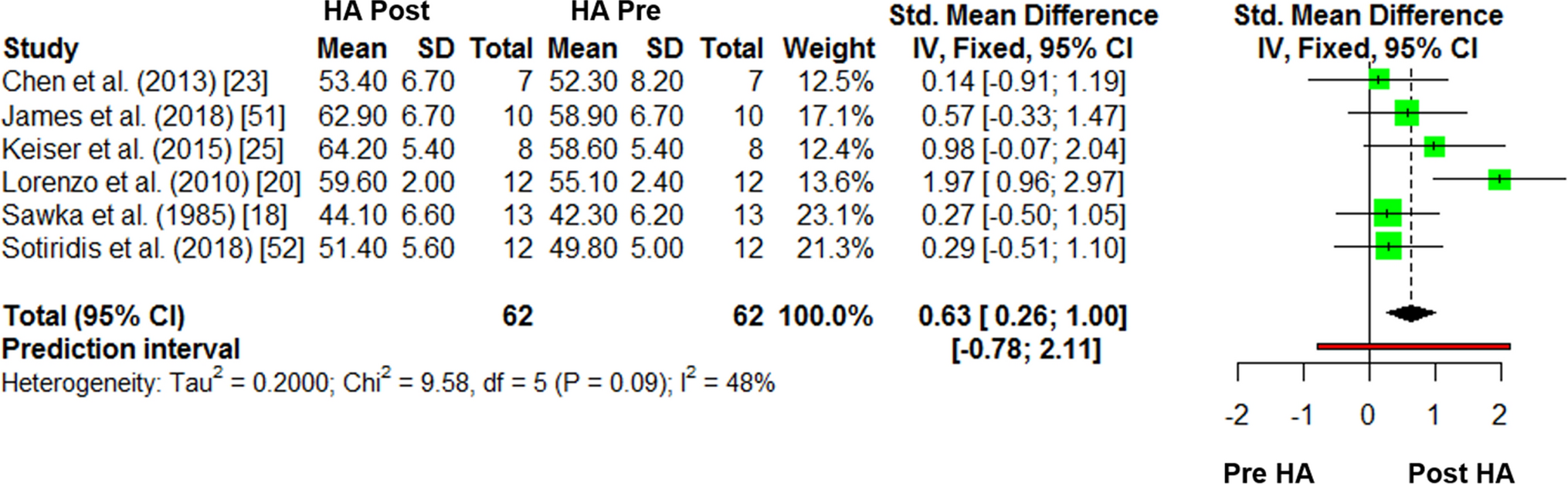
Figure from Brown et al. (2022) Sports Med. Open access paper shared under Creative Commons Attribution 4.0 International License.
The effect size of 0.63 (95% confidence interval 0.26 to 1.00) indicates a moderate sized beneficial effect of exercise training in the heat on V̇O2max.
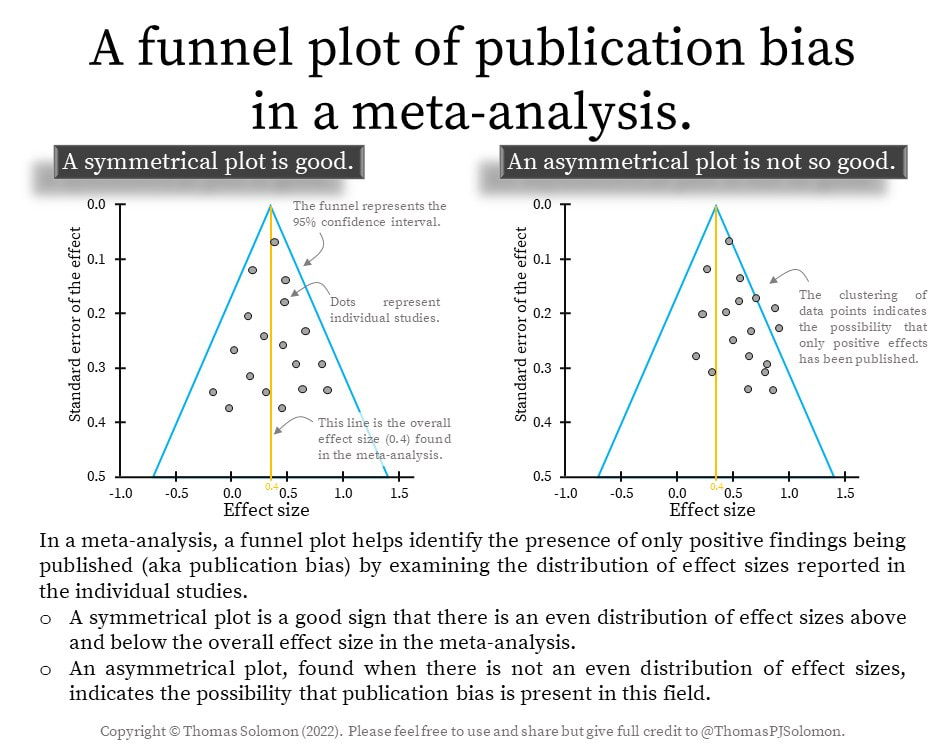
— In many areas of science, including exercise science, statistically significant results are published more frequently than negative findings. This is called publication bias — aka the presence of only positive findings being published). To help identify it, we will build funnel plots and use statistical tests to explore the distribution of effect sizes in the included studies.
— To examine statistical heterogeneity — aka how variable are the effect sizes between studies — several statistics will be calculated. These include the Q statistic and its corresponding χ2 test P-value, τ² and τ (pronounced “tau-squared” & “tau”), prediction intervals, and I². These are very jargon-filled. If you want more details, please read our registered protocol document.
— If the data allow, statistical methods (χ2 tests, pronounced “chi-squared”) will be used in subgroup analyses to determine whether the effect of post-exercise heat exposure is influenced by Training status (trained athletes vs. non-athletes/untrained people); Sex (male vs. female); and Heat exposure type (sauna vs. hot water immersion).
— If our risk of bias analysis reveals studies with a high risk of bias, a sensitivity analysis will be completed whereby the meta-analysis will be repeated with the “high risk” studies excluded.
How will we detect and minimise bias in our review?
Bias is always present in science — you can’t eradicate it. All studies, even randomised controlled trials, contain bias and systematic reviews introduce further bias. Bias can influence the interpretation of findings, which can influence how findings are used in practice. Therefore, bias must be identified and minimised using standard methods. We have mentioned many of these above but let’s summarize the approaches to help achieve minimal bias:
 We registered our review protocol on an publicly-available open-access registry at Open Science Foundation (see https://doi.org/10.17605/OSF.IO/256XZ) to ensure that our final approach matches up with our planned approach. When study data is collected and analysed, we also plan to store our raw data and final analyses on the same registry so it is freely available.
We registered our review protocol on an publicly-available open-access registry at Open Science Foundation (see https://doi.org/10.17605/OSF.IO/256XZ) to ensure that our final approach matches up with our planned approach. When study data is collected and analysed, we also plan to store our raw data and final analyses on the same registry so it is freely available.
We will complete several aspects of the review process independently and then cross-check our findings and reach an agreement through discussion. If necessary, consult our independent search strategy peer-reviewer to settle any disputes.
We only included randomised controlled trials where participants are randomised to receive a treatment intervention or a control intervention and the variables of interest are measured before and after the interventions in both groups.
We screened the included studies using the Cochrane Risk of Bias tool (RoB2). This helped identify bias arising from the randomization process, deviations from intended interventions, missing outcome data, the outcome measurement, and the authors’ selection of the reported results.
We will report who funded the individual studies and report authors’ affiliations. This will help identify conflicts of interest. We will also report our own conflicts of interest.
We will present the study inclusion/exclusion selection process in a Figure in accordance with a standardised method, the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) statement.
To ensure data accuracy, we will compare the magnitude and direction of effects reported in the included studies with how they appear in our database.
To identify meta-analytical bias, we will use standard statistical techniques to quantify between-study variability. We will also complete sensitivity analyses, which is an approach to repeat the meta-analysis with the exclusion of “high risk of bias” studies to determine whether they do or do not change the outcomes.
To help identify publication bias — that is the persistence of only positive findings being published — we will build funnel plots to determine whether effect sizes of individual studies are normally distributed around the average effect size.
We will make all our data and analytical methods publicly available and open-access.
During the review process, changes to the planned comparisons/outcomes may become necessary or new comparisons may need to be added. If this happens, time-stamped updates will be documented on our open-access registry at Open Science Foundation (see https://doi.org/10.17605/OSF.IO/256XZ).
— If we survive all of that, we will discuss the findings, write up the systematic review, submit it to a peer-reviewed journal, wait several months for peer-reviewers to critique our work, get accepted for publication, and then pay an extortionate publication fee to see the work published in a journal… HIGH-QUALITY SCIENCE TAKES A LONG TIME.
Will the findings be useful in application to training/coaching practice?
We hope so.
 What is our Rating of Perceived Scientific Enjoyment?
What is our Rating of Perceived Scientific Enjoyment?
So far, RP(s)E = 8 out of 10. But we reserve the right to dramatically change this.
What is the research question? The purpose of our systematic review is to answer the question:
Does post-exercise heat exposure improve endurance exercise performance?
Why are we asking this research question? — Heat acclimation is a popular training modality for athletes preparing for races in hot conditions.
— Traditionally, heat acclimation involves a purposeful series of training sessions in the heat (e.g. treadmill running in a sauna or heat chamber) during the month prior to the race — this is called “active” heat acclimation.
— Although this approach can induce adaptations associated with heat acclimation (increased sweat rate, shorter time to sweat onset, lower heart rate, and RPE during exercise), it has limitations because not everyone has access to a treadmill/bicycle in a sauna and not all of your sessions (e.g. technical mountain sessions) can be done in a sauna. Furthermore, because the heat forces you to train at a lower absolute intensity, “active” heat acclimation interferes with your normal training.
— Another common approach is “passive” heat acclimation in which one just sits in a sauna or hot tub daily without exercise. While some evidence shows this can effectively induce some aspects of heat acclimation such as lower heart rate, increased sweating, and lower core temperature (see here & here), this sometimes requires at least 1-hour of heat exposure per day.
— A contemporary approach to heat acclimation is adding “passive” heat exposure after exercise in normal temperatures. This can be achieved using a sauna or hot water immersion (having a bath) or by wearing a hot-water perfused body suit to maintain an elevated core body temperature after your exercise sessions. This might be more efficient than passive-only approaches.
— We recently noticed an increase in the number of studies examining the effects of post-exercise “passive” heat acclimation on exercise performance but no systematic review of the evidence exists. We will fill that gap with our review.
How are we going to answer the research question? — We will complete a systematic review of all known randomised controlled trials (RCTs) published in peer-reviewed journals examining the effect of post-exercise heat exposure on exercise performance. Note: RCTs are studies where participants are randomised to receive a treatment intervention or a control intervention and the variables of interest are measured before and after the interventions in both groups.
The text beyond this point goes pretty deep into our actual systematic review process. If you’re feeling nerdy and wanna learn more, keep reading. But, if you’re bored and have read enough, click here to skip ahead to our beer.
How did we search for published randomised controlled trials (RCTs)? — To ensure consistency in our search for papers, we dissected our question into Population, Interventions, Comparison group, & Outcomes. This helped us include only papers including the following:
Population — Healthy male or female adults (≥18 years of age) of any race/ethnicity, in any research setting.
Interventions — Daily exercise under thermoneutral (<25°C) environmental conditions coupled with post-exercise heat exposure (via any method including but not limited to a sauna or hot water immersion) for at least 2 consecutive days, with baseline and post-intervention exercise performance tests completed in either hot (≥25°C) or thermoneutral (<25°C) conditions. Daily exercise must be completed in normal ambient conditions and must include at least 30-mins of aerobic activities (walking, hiking, running, cycling, rowing, xc skiing, swimming, stair-stepping etc) at a moderate intensity or higher (≥40% heart rate reserve, ≥64% heart rate max, ≥46% V̇O2max, or RPE≥12 per ACSM activity guidelines). Post-exercise heat exposure must commence within 30-mins of exercise cessation.
Comparison group(s) — The control group must complete the same daily exercise intervention but without post-exercise heat exposure. Studies including additional comparator groups will be included since some work in this field has compared post-exercise heat exposure (passive acclimation) vs. during-exercise heat exposure (active acclimation) vs. no heat exposure.
Outcomes — The primary outcome is endurance exercise performance (assessed by time trial, time-to-exhaustion, or a race) in hot conditions (≥25°C). The secondary outcomes include (i) endurance exercise performance in cool conditions (<25°C); (ii) V̇O2max, economy/efficiency, and/or lactate threshold in hot and/or cool conditions; (iii) RPE, heart rate, sweat rate, and/or thermal comfort during exercise in hot and/or cool conditions; and (iv) all outcome variables in trained athletes vs. non-athletes. All outcomes must be measured at baseline and within 7-days of finishing the interventions.
Interventions — Daily exercise under thermoneutral (<25°C) environmental conditions coupled with post-exercise heat exposure (via any method including but not limited to a sauna or hot water immersion) for at least 2 consecutive days, with baseline and post-intervention exercise performance tests completed in either hot (≥25°C) or thermoneutral (<25°C) conditions. Daily exercise must be completed in normal ambient conditions and must include at least 30-mins of aerobic activities (walking, hiking, running, cycling, rowing, xc skiing, swimming, stair-stepping etc) at a moderate intensity or higher (≥40% heart rate reserve, ≥64% heart rate max, ≥46% V̇O2max, or RPE≥12 per ACSM activity guidelines). Post-exercise heat exposure must commence within 30-mins of exercise cessation.
Comparison group(s) — The control group must complete the same daily exercise intervention but without post-exercise heat exposure. Studies including additional comparator groups will be included since some work in this field has compared post-exercise heat exposure (passive acclimation) vs. during-exercise heat exposure (active acclimation) vs. no heat exposure.
Outcomes — The primary outcome is endurance exercise performance (assessed by time trial, time-to-exhaustion, or a race) in hot conditions (≥25°C). The secondary outcomes include (i) endurance exercise performance in cool conditions (<25°C); (ii) V̇O2max, economy/efficiency, and/or lactate threshold in hot and/or cool conditions; (iii) RPE, heart rate, sweat rate, and/or thermal comfort during exercise in hot and/or cool conditions; and (iv) all outcome variables in trained athletes vs. non-athletes. All outcomes must be measured at baseline and within 7-days of finishing the interventions.
— We planned our search strategy in January 2022 and, to maximise quality, we recruited Professor Janice Thompson (University of Birmingham, UK) to independently peer-review our strategy using standard guidelines (the 2015 Peer Review of Electronic Search StrategiesGuideline Statement).
— This process resulted in a specific search phrase that we could use when searching for papers.
— Our initial search was conducted in April 2022 and we searched several databases including MEDLINE, EMBASE, CENTRAL, and clinical trials databases for unpublished data (ClinicalTrials.gov, WHO International Clinical Trials Registry Platform, and EU Clinical Trials Register).
— Since many months will pass between the planning stage and the final data analysis, we will run the search again shortly before the final report is written to capture any new papers that have recently been published.
What did we do with all the studies after our search? — The search hits were downloaded into a reference manager software (Endnote) and we independently screened the studies, coding each study as “include” or “exclude” in line with our inclusion and exclusion criteria. Our initial search identified about 2000 studies, so this process took many hours.
— After our independent search and screening, we met to cross-check our findings and to agree on a final list of included studies. Any unresolved disagreements were resolved by our independent strategy peer-reviewer, Janice Thompson.
— Full-text versions of the included papers were downloaded and we independently assessed the quality of the individual studies using a standardised method (the Cochrane Risk of Bias tool), coding papers as either “low” or “high” risk of bias or “some concerns”. Once again, we met to cross-check our findings and agree on a final assessment of bias. This process will help us with the meta-analysis (more on that later).
— Next, we independently extracted data from the included papers. This included:
(i) Intervention details (inc. intervention duration, heat type/temperature/duration, exercise type/duration/intensity)
(ii) Number of subjects, mean, and standard deviation values for subject characteristics (e.g. age, sex, etc), and
(iii) Meanand standard deviation values for the outcome variables of interest.
— After extracting data, we met to cross-check our findings and agree on a final data set. The characteristics of included studies will be presented in a table and full data for the outcome variables of interest will be made publicly available. To ensure data accuracy, we will compare the magnitude and direction of effects reported in the included studies with how they appear in our database. (ii) Number of subjects, mean, and standard deviation values for subject characteristics (e.g. age, sex, etc), and
(iii) Meanand standard deviation values for the outcome variables of interest.
— Some of the data was not available in the papers so have requested it from the study authors. (This is the stage we are currently at and we are awaiting responses from study authors.) If authors don’t reply or do not share their data, we will use Web Plot Digitizer software to scan and extract data from the figures in the papers.
What will we do with the data? — Before any statistical analysis, we will first write a narrative of the included studies, in which we will “Describe, Interpret, Evaluate, and Conclude”. This will include a narrative of between-study heterogeneity (e.g. variation in sample sizes, study designs, interventions, subject types, etc, among the included studies). This is called a “qualitative” synthesis. After that, the “quantitative” synthesis (the meta-analysis) will begin…
— A meta-analysis determines the overall effect of an intervention. In this case, the overall effect of post-exercise heat exposure on exercise performance. Effect sizes for each study will be calculated as the between-group (treatment vs. control; or, heat vs. no heat) standardised mean difference (SMD) for each outcome in the included studies. Effect sizes are useful because they are a standardised measure of the experimental effect and can be used to infer the magnitude of the effect — an effect size of less than 0.2 is considered a trivial effect, 0.2 to 0.5 is small, 0.5 to 0.8 is moderate, 0.8 to 1.2 is a large, 1.2 to 2 is very large and greater than 2 is a huge effect.
— Effect size estimates will be compiled and meta-analysed using Meta-Essentials software.
— We will build forest plots to summarise the effect size estimates and the corresponding 95% confidence intervals, i.e. a margin of uncertainty — i.e. the range of plausible values within which the true effect size would be found 95% of the time if the data was repeatedly collected in different samples of people — basically, if the 95% confidence interval crosses zero, there is no effect. This will help us calculate the overall effect of post-exercise heat exposure.
The effect size of 0.63 (95% confidence interval 0.26 to 1.00) indicates a moderate sized beneficial effect of exercise training in the heat on V̇O2max.
— If the data allow, statistical methods (χ2 tests, pronounced “chi-squared”) will be used in subgroup analyses to determine whether the effect of post-exercise heat exposure is influenced by Training status (trained athletes vs. non-athletes/untrained people); Sex (male vs. female); and Heat exposure type (sauna vs. hot water immersion).
— If our risk of bias analysis reveals studies with a high risk of bias, a sensitivity analysis will be completed whereby the meta-analysis will be repeated with the “high risk” studies excluded.
How will we detect and minimise bias in our review? Bias is always present in science — you can’t eradicate it. All studies, even randomised controlled trials, contain bias and systematic reviews introduce further bias. Bias can influence the interpretation of findings, which can influence how findings are used in practice. Therefore, bias must be identified and minimised using standard methods. We have mentioned many of these above but let’s summarize the approaches to help achieve minimal bias:
We registered our review protocol on an publicly-available open-access registry at Open Science Foundation (see https://doi.org/10.17605/OSF.IO/256XZ) to ensure that our final approach matches up with our planned approach. When study data is collected and analysed, we also plan to store our raw data and final analyses on the same registry so it is freely available.
We will complete several aspects of the review process independently and then cross-check our findings and reach an agreement through discussion. If necessary, consult our independent search strategy peer-reviewer to settle any disputes.
We only included randomised controlled trials where participants are randomised to receive a treatment intervention or a control intervention and the variables of interest are measured before and after the interventions in both groups.
We screened the included studies using the Cochrane Risk of Bias tool (RoB2). This helped identify bias arising from the randomization process, deviations from intended interventions, missing outcome data, the outcome measurement, and the authors’ selection of the reported results.
We will report who funded the individual studies and report authors’ affiliations. This will help identify conflicts of interest. We will also report our own conflicts of interest.
We will present the study inclusion/exclusion selection process in a Figure in accordance with a standardised method, the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) statement.
To ensure data accuracy, we will compare the magnitude and direction of effects reported in the included studies with how they appear in our database.
To identify meta-analytical bias, we will use standard statistical techniques to quantify between-study variability. We will also complete sensitivity analyses, which is an approach to repeat the meta-analysis with the exclusion of “high risk of bias” studies to determine whether they do or do not change the outcomes.
To help identify publication bias — that is the persistence of only positive findings being published — we will build funnel plots to determine whether effect sizes of individual studies are normally distributed around the average effect size.
We will make all our data and analytical methods publicly available and open-access. During the review process, changes to the planned comparisons/outcomes may become necessary or new comparisons may need to be added. If this happens, time-stamped updates will be documented on our open-access registry at Open Science Foundation (see https://doi.org/10.17605/OSF.IO/256XZ).
Will the findings be useful in application to training/coaching practice? We hope so.
What is our Rating of Perceived Scientific Enjoyment? So far, RP(s)E = 8 out of 10. But we reserve the right to dramatically change this.
 What was the beer called?
Suvila.
Which brewery made it?
Põhjala (Tallinn, Estonia).
What type of beer is it?
Hazy DDH (Double Dry Hopped) IPA.
How strong is the beer?
3.8% ABV.
How would I describe this beer?
Gently citrusy on the nose, smooth on the tongue, slightly hoppy to the taste but rather watery. Despite that, Suvila is a highly drinkable-in-the-sun type of IPA with a mildly citrusy aftertaste.
What is my Rating of Perceived Beer Enjoyment?
RP(be)E(r) = 8 out of 10.
What was the beer called?
Suvila.
Which brewery made it?
Põhjala (Tallinn, Estonia).
What type of beer is it?
Hazy DDH (Double Dry Hopped) IPA.
How strong is the beer?
3.8% ABV.
How would I describe this beer?
Gently citrusy on the nose, smooth on the tongue, slightly hoppy to the taste but rather watery. Despite that, Suvila is a highly drinkable-in-the-sun type of IPA with a mildly citrusy aftertaste.
What is my Rating of Perceived Beer Enjoyment?
RP(be)E(r) = 8 out of 10.  What was the beer called?
Pabst Blue Ribbon.
Which brewery made it?
Pabst Brewing Company (San Antonio, USA).
What type of beer is it?
American Adjunct Lager.
How strong is the beer?
4.74% ABV.
How would I describe this beer?
Cheap. For a 6-pack of pints, this will set you back $6.60 (even at a high-end store). Take that inflation. It’s also the perfect complement to summer temperatures, river lounging, post-exercise, camping, and working in the sun days. As far as cheaper options go it’s my favorite (no thanks Coors, Bud, or Miller). Taste-wise, there is a hint of hops, a solid amount of breadiness, and a crisp finish that is enough to make it clear you are drinking beer. Perceived enjoyment is heavily influenced by the setting.
What is my Rating of Perceived Beer Enjoyment?
RP(be)E(r) = 8 out of 10.
What was the beer called?
Pabst Blue Ribbon.
Which brewery made it?
Pabst Brewing Company (San Antonio, USA).
What type of beer is it?
American Adjunct Lager.
How strong is the beer?
4.74% ABV.
How would I describe this beer?
Cheap. For a 6-pack of pints, this will set you back $6.60 (even at a high-end store). Take that inflation. It’s also the perfect complement to summer temperatures, river lounging, post-exercise, camping, and working in the sun days. As far as cheaper options go it’s my favorite (no thanks Coors, Bud, or Miller). Taste-wise, there is a hint of hops, a solid amount of breadiness, and a crisp finish that is enough to make it clear you are drinking beer. Perceived enjoyment is heavily influenced by the setting.
What is my Rating of Perceived Beer Enjoyment?
RP(be)E(r) = 8 out of 10. 
That is all for this month's nerd alert. We hope to have succeeded in helping you learn a little more about the developments in the world of running science. If not, we hope you enjoyed a nice beer…
If you find value in our nerd alerts, please help keep them alive by sharing them on social media and buying us a beer at buymeacoffee.com/thomas.solomon. For more knowledge, join Thomas @thomaspjsolomon on Twitter, follow @veohtu on Facebook and Instagram, subscribe to Thomas’s free email updates at veothu.com/subscribe, and visit veohtu.com to check out Thomas’s other Articles, Nerd Alerts, Free Training Plans, and his Train Smart Code. To learn while you train, you can even listen to Thomas’s articles by subscribing to the Veohtu podcast.
Until next month, stay nerdy and keep empowering yourself to be the best athlete you can be...
If you find value in our nerd alerts, please help keep them alive by sharing them on social media and buying us a beer at buymeacoffee.com/thomas.solomon. For more knowledge, join Thomas @thomaspjsolomon on Twitter, follow @veohtu on Facebook and Instagram, subscribe to Thomas’s free email updates at veothu.com/subscribe, and visit veohtu.com to check out Thomas’s other Articles, Nerd Alerts, Free Training Plans, and his Train Smart Code. To learn while you train, you can even listen to Thomas’s articles by subscribing to the Veohtu podcast.
Until next month, stay nerdy and keep empowering yourself to be the best athlete you can be...
Everyday is a school day.
Empower yourself to train smart.
Think critically. Be informed. Stay educated.
Empower yourself to train smart.
Think critically. Be informed. Stay educated.
Disclaimer: We occasionally mention brands and products but it is important to know that we are not sponsored by or receiving advertisement royalties from anyone. We have conducted biomedical research for which we have received research money from publicly-funded national research councils and medical charities, and also from private companies. We have also advised private companies on their product developments. These companies had no control over the research design, data analysis, or publication outcomes of our work. Any recommendations we make are, and always will be, based on our own views and opinions shaped by the evidence available. The information we provide is not medical advice. Before making any changes to your habits of daily living based on any information we provide, always ensure it is safe for you to do so and consult your doctor if you are unsure.
If you find value in these nerd-alerts, please help keep them alive and buy us a beer:
If you enjoy this free content, please like and follow @veohtu, @mjlaye and @thomaspjsolomon and share these posts on your social media pages.

About the authors:
Matt and Thomas are both passionate about making science accessible and helping folks meet their fitness and performance goals. They both have PhDs in exercise science, are widely published, have had their own athletic careers, and are both performance coaches alongside their day jobs. Originally from different sides of the Atlantic, their paths first crossed in Copenhagen in 2010 as research scientists at the Centre for Inflammation and Metabolism at Rigshospitalet (Copenhagen University Hospital). After discussing lots of science, spending many a mile pounding the trails, and frequent micro brew pub drinking sessions, they became firm friends. Thomas even got a "buy one get one free" deal out of the friendship, marrying one of Matt's best friends from home after a chance encounter during a training weekend for the CCC in Schwartzwald. Although they are once again separated by the Atlantic, Matt and Thomas meet up about once a year and have weekly video chats about science, running, and beer. This "nerd alert" was created as an outlet for some of thehundreds of scientific papers craft beers they read drink each month.
Matt and Thomas are both passionate about making science accessible and helping folks meet their fitness and performance goals. They both have PhDs in exercise science, are widely published, have had their own athletic careers, and are both performance coaches alongside their day jobs. Originally from different sides of the Atlantic, their paths first crossed in Copenhagen in 2010 as research scientists at the Centre for Inflammation and Metabolism at Rigshospitalet (Copenhagen University Hospital). After discussing lots of science, spending many a mile pounding the trails, and frequent micro brew pub drinking sessions, they became firm friends. Thomas even got a "buy one get one free" deal out of the friendship, marrying one of Matt's best friends from home after a chance encounter during a training weekend for the CCC in Schwartzwald. Although they are once again separated by the Atlantic, Matt and Thomas meet up about once a year and have weekly video chats about science, running, and beer. This "nerd alert" was created as an outlet for some of the
To read more about the authors, click the buttons:
Copyright © Thomas Solomon and Matt Laye. All rights reserved.